

FastAPI gives you a lot out of the box: async concurrency, Pydantic validation, middleware, error handling, automatic docs, and dependency injection. It’s so intuitive that many teams can get up and running quickly - sometimes without thinking through system design.
In this article, we’ll look at common pitfalls and how to fix them with practical patterns for project structure and router composition, lifespan vs. request-scoped resources, and concurrency (including event-loop stalls and offloading).
Project structure
When a project starts, features are prioritized over structure. As complexity grows, locating endpoint code gets harder, and duplication and circular imports creep in. While the exact structure varies by business needs, most web servers share similar concerns, and could consist of the following folders, separated on the basis of functionality:
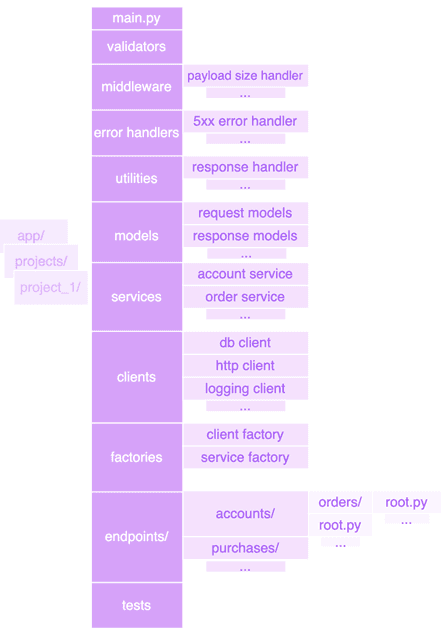
main.py - create app; lifespan wiring; register middleware and error handlers.
validators/ - reusable input checks (IDs, enums, business rules) used by Pydantic.
middleware/ - cross-cutting layers (e.g., payload-size guard).
error_handlers/ - exception-HTTP response mapping;
utilities/ - small helpers (response wrappers, pagination, formatting).
models/ - Pydantic models for validating incoming requests and outgoing responses;
services/ - business logic; orchestrates repositories/clients.
clients/ - clients: DB engine/sessionmaker, HTTP client, logging/tracing adapters.
factories/ - dependency-injection-friendly builders for clients/services.
endpoints/ - APIRouters grouped by business domain (accounts/, purchases/, orders/);
tests/ - unit/integration tests; use dependency overrides and test settings.
The tricky part isn’t the folders - it’s the parent/child router relationship.
Let’s take this API design as the goal.
/accounts
/accounts/{account_id}
/accounts/{account_id}/orders
/accounts/{account_id}/orders/{order_id}To achieve that, we’ll create two routers:
child router:
location: app/endpoints/accounts/orders/root.py
serves: /{account_id}/orders
orders = APIRouter(
prefix="/{account_id}/orders",
tags=["orders"]
)
@orders.get("/")
async def list_orders(
account_id: Annotated[UUID, Path()],
last_id: str | None = None,
limit: int = 50
):
return {
"account": str(account_id),
"items": [],
"next": None
}
@orders.post("/")
async def create_order(
account_id: Annotated[UUID, Path()]
): return { "account": str(account_id), "ok": True}parent router:
location: app/endpoints/accounts/root.py
serves: /accounts
from .orders.root import orders as orders_router
accounts = APIRouter(
prefix="/accounts",
tags=["accounts"]
)
async def load_account(
account_id: Annotated[UUID, Path()]
): return {"id": account_id}
@accounts.get("/")
async def list_accounts(): return [{"id": "12345"}]
@accounts.get("/{account_id}")
async def get_account(account_id: UUID):
return {"id": account_id}
accounts.include_router(
orders_router,
# DI imposed on the order routes
dependencies=[Depends(load_account)],
)This structure ensures that “orders” cannot be accessed without specifying an account_id, and it allows developers to quickly identify the location of an endpoint and create multiple layers of child routers. With this design, it is possible to reuse the “orders router” in other places with adjusted dependencies.
Factory pattern and dependency injection
A factory encapsulates the construction of clients and services by using the app state and various environment variables, and configurations.
A Factory can be used to manage:
- Cloud clients - SQS, S3, SNS, etc.
- Database clients - Redis, Postgres, Mongo
- Configuration wiring - application-level and request-level (relevant if each client has a specific configuration)
- Service classes, encapsulating business logic - AccountService, OrderService.
- Auxiliary classes - loggers, user sessions, etc.
class Factory:
@classmethod
async def get_http_client(
cls,
settings
): return AsyncClient(base_url=settings.api)
@classmethod
async def get_account_service(
cls,
request: Request
) -> AccountService:
settings: Settings = request.app.state.settings
return AccountService(
client=await cls.get_http_client(settings),
)Based on this example, we see that a well-designed factory can be plugged into FastAPI’s dependency injection with minimal effort.
@app.get("/accounts/{account_id}")
async def account_overview(
account_id: str,
account_service: Annotated[
AccountService,
Depends(Factory.get_account_service)
]
):
r = await account_service.fetch_profile(account_id)
if not r:
raise HTTPException(
status_code=404,
detail="Account not found"
)
return rThe endpoint stays thin and readable: it validates input, orchestrates services and maps internal results to HTTP responses. Business logic lives outside the endpoint; the handler focuses on HTTP concerns (wiring, status codes, and formatting).
The Factory can greatly simplify access to different loggers on the server.
class Factory
@classmethod
def get_root_logger(cls) -> logging.Logger:
return logging.getLogger("app")
@classmethod
def get_request_logger(
cls,
request: Request
) -> logging.LoggerAdapter:
base = cls.get_root_logger()
return logging.LoggerAdapter(
base,
{
"path": request.url.path,
"method": request.method,
"corr_id": request.state.corr_id,
}
)Now all types of loggers can easily be instantiated via the Factory in endpoints:
acc_ser_dep = Annotated[
AccountService,
Depends(Factory.get_account_service),
]
log_dep = Annotated[
LoggerAdapter,
Depends(Factory.get_request_logger),
]
@app.get("/accounts/{account_id}")
async def account_overview(
account_id: str,
account_service: acc_ser_dep,
logger: log_dep,
):
r = await account_service.fetch_profile(account_id)
if not r:
logger.warning(
"Account not found",
extra={"account_id": account_id},
)
raise HTTPException(404, "Account not found")
return rA request-scoped logger needs a correlation ID to stitch a request’s logs into a coherent story. It’s common to generate the ID inside endpoints, but that leads to repetition. It’s more efficient to use a small middleware that sets the ID once per request and can be extended to include user_id, firm_id, and other context:
@app.middleware("http")
async def corr_middleware(request: Request, call_next):
_id = request.headers.get("X-Request-ID") or str(uuid4())
request.state.corr_id = _id
response = await call_next(request)
response.headers["X-Request-ID"] = _id
return responseGoing back to the factory example, there was an easy-to-miss step that simplifies the dependency injection architecture.
settings: Settings = request.app.state.settingsThis line assumes Settings is initialized on startup (main.py):
@asynccontextmanager
async def lifespan(app: FastAPI):
app.state.settings = Settings()
yield
await Factory.aclose()
app = FastAPI(lifespan=lifespan)Objects attached to app.state are lifespan-scoped for each FastAPI worker process and should be closed in the shutdown phase.
Lifespan vs. Request scope
Lifespan objects can persist across many requests and live for the lifetime of the server. Using app.state is not the only way to hold them (singletons, cached objects with keys, etc.), but it is the most convenient option in FastAPI.
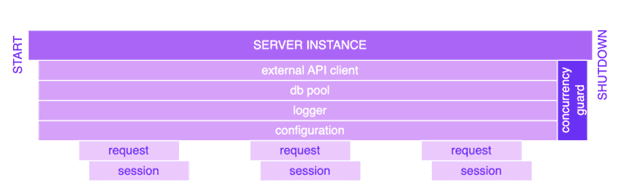
A request-scoped “session”, which aggregates request-specific state required by business logic (e.g., correlation_id, user_id), will die right after the request completes.
Throughout the server lifetime, we can use objects attached to app.state (DB pool, HTTP clients, etc.). When the server shuts down we trigger the closure of these objects, and we have a special logic for that.
class Factory:
@classmethod
async def aclose(cls):
await app.state.db_pool.aclose()
await app.state.external_http_client.aclose()
...The fact that an object was garbage-collected does not mean the corresponding connections have been closed. That is why we have await Factory.aclose() in the server lifespan.
The same pattern can be applied to request-scoped clients via the Factory.
class Factory:
@classmethod
async def get_account_service(cls):
settings: Settings = request.app.state.settings
account_service = AccountService(
client=await cls.get_http_client(settings),
)
try:
yield account_service
finally:
await account_service.client.aclose()In the example above account_service is deleted only after closing the connections of the HTTP client, so that its sockets are released immediately.
Concurrency
Settings is a good example of a lifespan object that requests can access concurrently via app.state.settings. Ideally, lifespan objects should be read-only and should not reference request-scoped objects (so those can be garbage-collected).
Otherwise, there is a risk of memory leaks and race conditions. In general, anything shared across requests must have concurrency guards built in (thread/async-safe).
For sharing state between different requests or even workers, external storage is a safer and more scalable option. But what happens if two requests of the same worker try to write into the settings around the same time? Let’s consider this example:
cfg = request.app.state.settings
old = cfg.threshold
await some_async_call() # yields, other requests run here
request.app.state.settings.threshold = old + 1This code will leave the shared state inconsistent. If it is absolutely necessary to update the state, a lock should be used
app.state.settings_lock = asyncio.Lock()
async def update_settings(app, patch: dict):
async with app.state.settings_lock:
settings = app.state.settings
app.state.settings = settings.model_copy(
update=patch,
)With this function in place, the settings can be updated safely:
await update_settings(request.app,{"threshold":old+1})Let’s consider an example without await some_async_call()
cfg = request.app.state.settings
old = cfg.threshold
request.app.state.settings.threshold = old + 1The code runs as a single block on the event loop thread. That ensures the integrity of the state but increases the latency of the server. FastAPI does not automatically move synchronous work from the event loop thread to ThreadPool. It must be done explicitly by a developer.
@app.get("/update-state")
async def update_state():
# moves to threadpool
await anyio.to_thread.run_sync(
update_settings_sync
)
return {"ok": True}There is one more way to do it via Depends, but it’s not worth a detailed exploration, because having multiple threads write to a shared state is not the right design.
Both examples of offloading synchronous work will work well when no shared state updates are involved.
@app.post("/update-state")
async def update_state(
result: dict = Depends(update_settings_dep)
):
return resultA solid grasp of how the event loop interacts with synchronous and asynchronous code helps a developer find the most effective solution.
Event-loop exhaustion often occurs when async endpoints perform heavy sync work. See the examples below:
def cpu_heavy(n: int) -> float:
# Python CPU; never yields
s = 0.0
for i in range(n):
s += math.sqrt(i)
return s
@app.get("/cpu")
async def cpu(n: int = 10_000_000):
# heavy CPU on the loop, requests on the worker stall
return {"sum": cpu_heavy(n)}
@app.get("/sleep")
async def sleep(ms: int = 500):
# blocking sleep holds the loop
time.sleep(ms / 1000)
return {"slept_ms": ms}
@app.get("/io")
async def io():
# stalling call until the socket completes
r = requests.get(
"https://httpbin.org/delay/1",
timeout=5,
)
return {"status": r.status_code}Event-loop exhaustion is very hard to diagnose. A developer would have to see which requests were happening around the time of the stalled request and walk through the logic to identify possible culprits.
Typically, a special loop_lag function is created on the server (via lifespan) to report extended lags to OpenTelemetry, but that signal alone rarely pinpoints the root cause.
async def lag_probe(
interval: float = 0.5,
warn_ms: float = 100.0
):
loop = asyncio.get_running_loop()
next_t = loop.time() + interval
while True:
await asyncio.sleep(interval)
now = loop.time()
lag_ms = max(0.0, (now - next_t) * 1000.0)
if lag_ms > warn_ms:
print(f"event_loop_lag_ms={lag_ms:.1f}")
next_t += intervalA typical anti-pattern in FastAPI is having one endpoint call another endpoint. The usual motive is to avoid duplicating code that was already compartmentalized elsewhere and to paper over the absence of a proper service interface. This pattern adds unnecessary latency and overhead - extra serialization, authentication, and logging.
If this anti-pattern is applied systematically across endpoints, it quickly gets out of control, amplifying load and latency. It becomes harder to establish the scaling policy based on the number of incoming requests due to their exponential nature. Needless to say, over time even small design mistakes snowball into big problems.
Another anti-pattern is spinning up multiple workers in a server that depends on heavy in-memory structures (LLMs, big Pydantic models, large caches, etc.). Each worker is a separate process with its own event loop, so those objects are replicated per worker, increasing memory and CPU consumption. If one worker spikes past the container’s limits, the pod will be OOM-killed (e.g., by Kubernetes) before Gunicorn can recycle that worker.
For these workloads, prefer offloading inference to a separate service (e.g., an inference server like HuggingFace) or running a single worker per pod. In general, more pods outperform the “more workers per pod” design, but there is a caveat related to active database connections. If a worker uses a connection pool, the database’s CPU will go up, because each connection reserves CPU (≈ pods × workers × pool_size). This, in its turn, leads to higher latency, connection errors and the overall performance degradation.
There’s no silver bullet. Patterns and best practices help, but each solution should be shaped by the specific business context.